Automating quality control for language at Transloadit
I was writing internal documentation on how I set up automated language checking at Transloadit. Halfway through, I figured this could be useful to the rest of the world 🌎 as well, so I rewrote it in a more generic fashion. I will attempt to first give a high-level overview of the problem, before driving all the way down to the low-level nuts and bolts of solving it. I hope you'll enjoy, here goes!
At Transloadit, we have been extracting all significantly sized chunks of text (documentation, blog posts, static pages) into a separate content repository.
Up until this migration, our text was scattered across MySQL tables, templates, and HTML files. A big soup of content, layout, code, and locations. Developers were able to access all of it - but without much joy. Non-developers didn't stand a chance.
We thought it would be interesting to see whether we could attract technical writers and give them full access to our content. We imagined they would be able to use the GitHub web interface in wiki-like fashion, so they could improve our language without being distracted by code, accidentally changing it, or needing much skill in that area.
This has not yet reached its full potential, but:
- as developers we are already enjoying working on the (purely Markdown) content
- having all content in a separate repository opens doors to other cool possibilities, like automated quality control, or: Continuous Integration
Continuous integration
Continuous Integration is a concept normally associated with code. ThoughtWorks explains it as follows:
Continuous Integration (CI) is a development practice that requires developers to integrate code into a shared repository several times a day. Each check-in is then verified by an automated build, allowing teams to detect problems early.
At Transloadit, we were already using this for all of our code. But could we also use this for our English?
This question was especially relevant to us, because, while the majority of our customers lives in the United States, Transloadit is Berlin-based, and nobody on our current team is a native English speaker.
Considering how damaging language errors can be when people are still in the early stages of evaluating a product - having some extra checks in place is all the more important to us.
We are targeting poor content quality in three areas:
Inconsiderate writing
To quote npm weekly:
Odds are none of us intends to exclude or hurt fellow members of the community, but polarizing and gender-favoring language has a way of slipping into what we write. Sometimes it’s a big help to have a second set of eyes that can look things over, notice what we’ve overlooked, and nudge us towards being more considerate and inclusive. Alex helps "catch insensitive, inconsiderate writing" by identifying possibly offensive language and suggesting helpful alternatives.
To install alex, we run a simple npm install --save alex.
Alex isn’t as smart as a human, but it tries its best and is sometimes overly happy to let you know something may be insensitive.
This means there may occasionally be false positives and since we don't want alex' warnings to be fatal, we are using
node_modules/.bin/alex || true
That way, we get to see the language that alex thinks could be improved, but we won't make those suggestions critical.
For example
74:74-74:76 warning $(he) may be insensitive, use $(they), $(it) instead
We are currently rewriting our docs to be more inclusive, thanks to this project.
Messy formatting
Our text files are in the Markdown format. This format was chosen, because it:
- is fairly easy to digest for humans and computers,
- has a great ecosystem of tools surrounding it, and
- offers a good separation between a document's structure, and its layout. We can specify that something is emphasized, but not Comic Sans. Those decisions are left to the designers.
Often, there are multiple ways to achieve the same goal in Markdown. As with code, it helps to settle on a convention, and force every contributor to follow it. By taking away some of this (useless) artistic freedom, the resulting document looks well maintained, and invites further contribution.
For this, we are using mdast with a lint plugin:
npm install --save mdast mdast-lint
Since we don't want to check external projects (like mdast itself) or re-check built artifacts, we are excluding a few locations
'_site/' >> .mdastignore
'node_modules/' >> .mdastignore
We then saved the following convention in .mdastrc, but this is of course dependent on your
settings and
lint preferences
{
"plugins": {
"lint": {
"blockquote-indentation": 2,
"emphasis-marker": "*",
"first-heading-level": false,
"link-title-style": "\"",
"list-item-indent": false,
"list-item-spacing": false,
"no-shell-dollars": false,
"maximum-heading-length": false,
"maximum-line-length": false,
"no-duplicate-headings": false,
"no-blockquote-without-caret": false,
"no-file-name-irregular-characters": true,
"no-file-name-outer-dashes": false,
"no-heading-punctuation": false,
"no-html": false,
"no-multiple-toplevel-headings": false,
"ordered-list-marker-style": ".",
"ordered-list-marker-value": "one",
"strong-marker": "*"
}
},
"settings": {
"gfm": true,
"yaml": true,
"rule": "-",
"ruleSpaces": false,
"ruleRepetition": 70,
"emphasis": "*",
"listItemIndent": "1",
"incrementListMarker": false,
"spacedTable": false
}
}
Then we lint for the first time
node_modules/.bin/mdast --frail .
This may return
_posts/2015-09-15-spelling.md
246:1 warning Use spaces instead of hard-tabs no-tabs
As a bonus, mdast can even attempt to repair this automatically
node_modules/.bin/mdast --output .
We were impressed by how much mdast was able to fix. Make sure, however that your files are committed to Git before running this command. You will want to review the changes made, and revert them if needed. It will most likely take a few iterations to get this into a good place.
Spelling errors
William Dutton, director of the Oxford Internet Institute at Oxford University, says in Spelling mistakes 'cost millions' in lost online sales that in some informal parts of the internet, such as Facebook, there is greater tolerance towards spelling and grammar.
However, there are other aspects, such as a home page or commercial offering that are not among friends and which raise concerns over trust and credibility. In these instances, a misspelt word could be a killer issue.
You had me at 'concerns'. Let's get to work. For spell checking in Markdown documents, we are using
npm install --save markdown-spellcheck.
It may not catch grammar and many other subtleties ("it's" vs "its"), but at least many of my unfortunate stubborn mistakes are caught before reaching production:
- my own fantasy English ("symbiose" vs "symbiosis")
- stubborn misfires ("editted" vs "edited"), and
- mixing British with US English ("summarise" vs "summarize")
(in my defense: I'm not a native English speaker 😄)
Markdown-spellcheck will even automatically skip code blocks and other Markdowny things - but
obviously we still had to manually ignore things like Transloadit & FFmpeg
'Transloadit' >> .spelling
'FFmpeg' >> .spelling
We are now ready to check our Markdown files for spelling mistakes
node_modules/.bin/mdspell \
--report \
--en-us \
--ignore-numbers \
--ignore-acronyms \
**/*.md \
_layouts/*.html \
_includes/*.html \
*.html
This might return that "editted" is not a word.
First run
There is a good chance the first run uncovers many issues, both with your documents and with the
dictionary. It is therefore a good idea to run mdspell without the --report flag so it will
enter the default interactive mode.
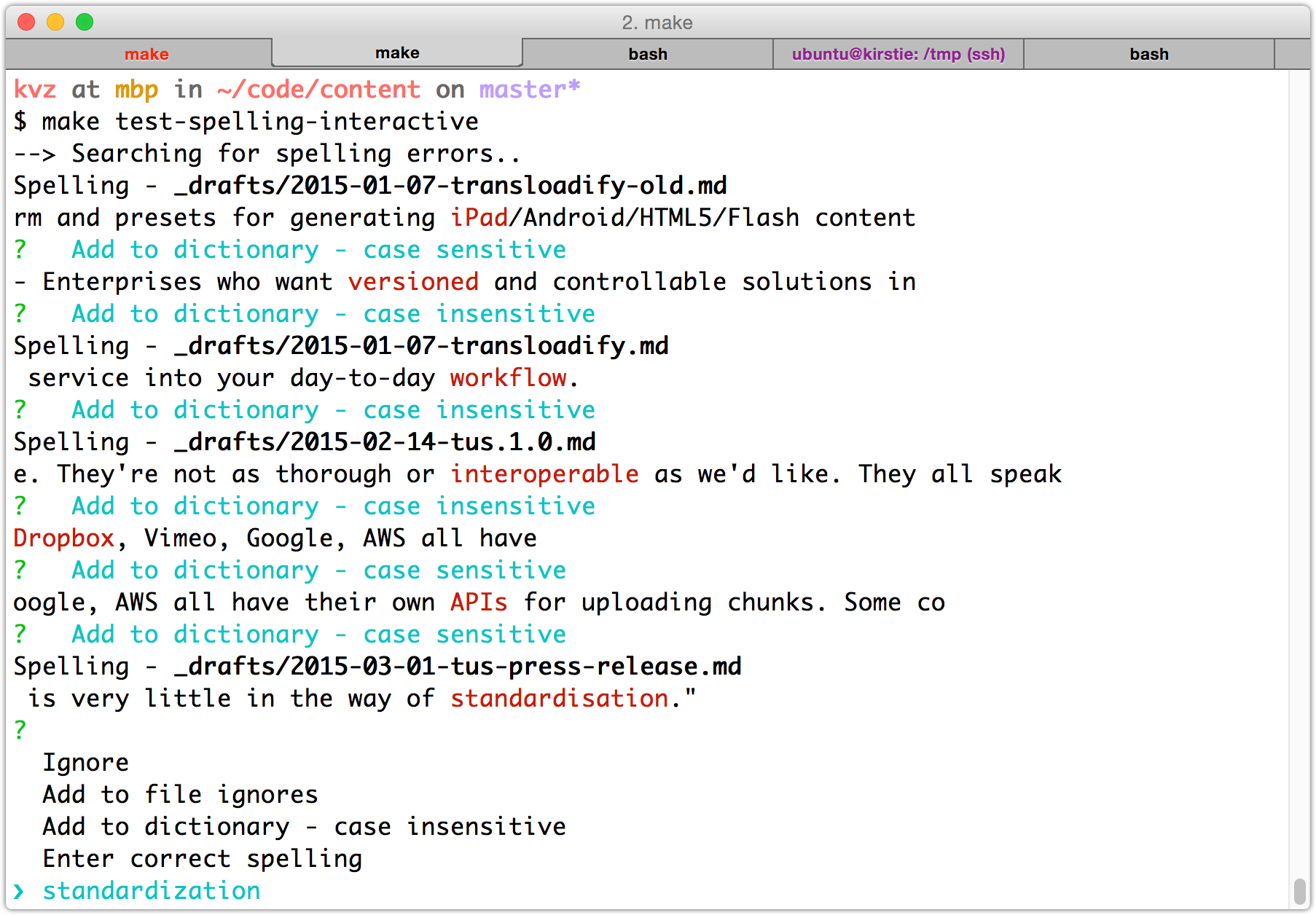
This will allow you to exclude certain files and build a personalized dictionary inside .spelling.
This will probably take a while, but it could make for a great activity when you want to be
productive on an otherwise uninspired afternoon.
As you add new content, you will sometimes have to add words to the allowlist as well. But at least you will know that all cases where words stray from the dictionary, will be deliberate. And that's a good feeling.
Combine
Now let's put this all together.
Since we installed all these tools from npm, it might make sense to use npm run scripts. However, in our case, I chose a Makefile, simply because we like TABing through shell autocompletion and so that we can have the same developer entry point in all of our projects, whether written in Node.js, Bash, or Go.
SHELL := /usr/bin/env bash
tstArgs :=
tstPattern := **/*.md _layouts/*.html _includes/*.html *.html
.PHONY: fix-markdown
fix-markdown:
@echo "--> Fixing Messy Formatting.."
@node_modules/.bin/mdast --output .
.PHONY: test-inconsiderate
test-inconsiderate:
@echo "--> Searching for Inconsiderate Writing (non-fatal).."
@node_modules/.bin/alex $(tstArgs) || true
.PHONY: test-spelling
test-spelling:
@$(MAKE) test-spelling-interactive tstArgs=--report
.PHONY: test-spelling-interactive
test-spelling-interactive:
@echo "--> Searching for Spelling Errors.."
@node_modules/.bin/mdspell \
$(tstArgs) \
--en-us \
--ignore-numbers \
--ignore-acronyms \
$(tstPattern)
.PHONY: test-markdown-lint
test-markdown-lint:
@echo "--> Searching for Messy Formatting.."
@node_modules/.bin/mdast --frail $(tstArgs) .
.PHONY: test
test: test-inconsiderate test-spelling test-markdown-lint
@echo "All okay : )"
Now we can run make test to see if all our checks pass.
We can run make test-spelling to only zoom in on spelling mistakes, or
make test-spelling-interactive if we want to enter interactive mode after writing content with a
lot of new words that are unlikely to be in the dictionary already.
If you have
Bash Completion, just type
make, press TAB, and see all the available shortcuts.
Automate
To automate testing, we will require a Continuous Integration server.
Travis CI, Strider, and Drone.io, all fit the bill. As long as we have a central place that will execute code in a reliable and repeatable fashion whenever a change to your repository is made.
We are using Jenkins for private projects, and I created three new chained jobs for our content repository:
content-buildturns our Markdown into static HTML content via Jekyll, then triggers:content-testruns all the commands in this post, then triggers:content-injectstores the HTML into our website, then triggers:website-build,website-test,website-deploy. A chain we had already set up to deploy our website.
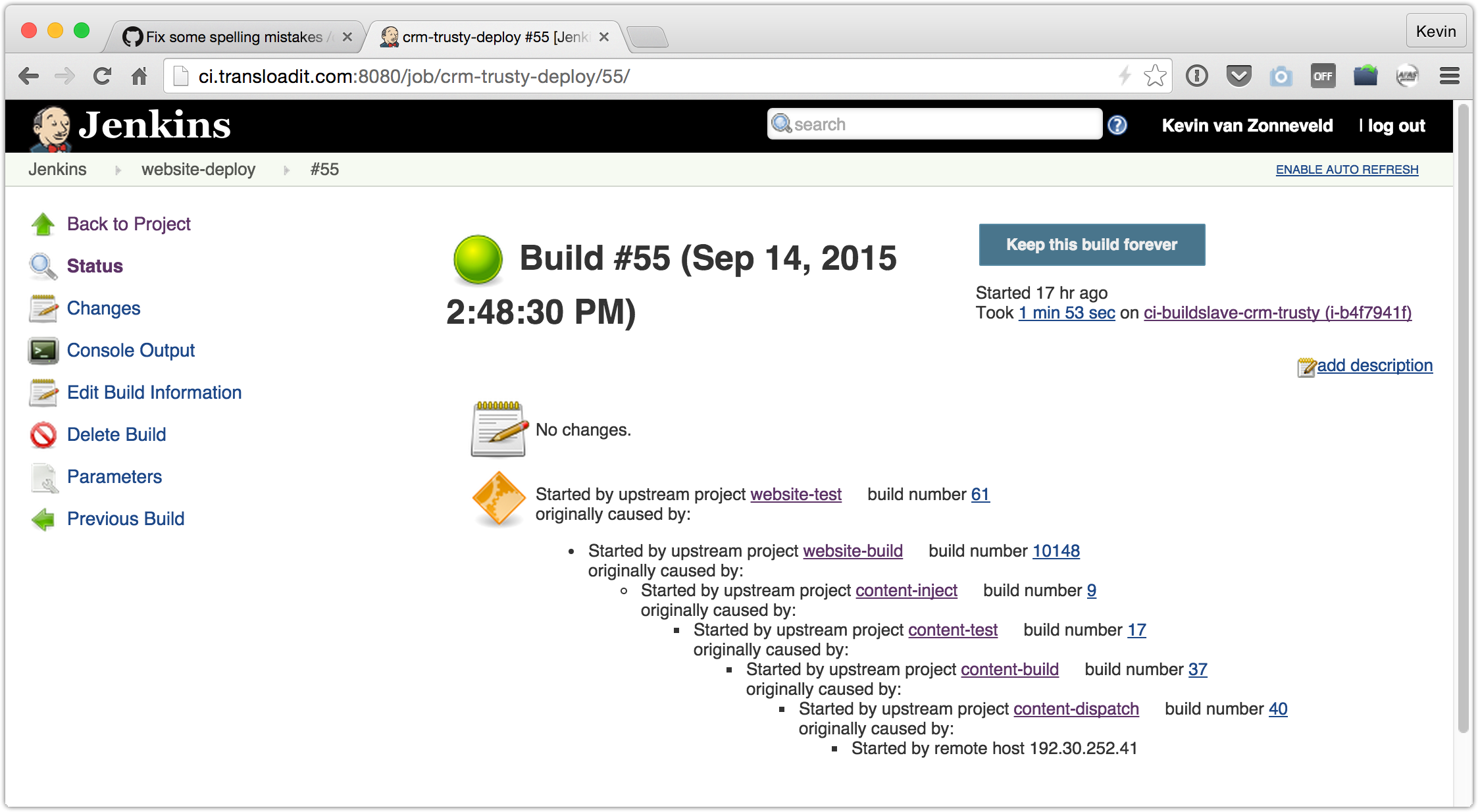
New content can now only be injected and deployed if all checks pass. It is a pretty long chain, but luckily a machine takes care of that. 😄
And when that machine detects typos in new content, we have a Slack integration set up so we get notified immediately.
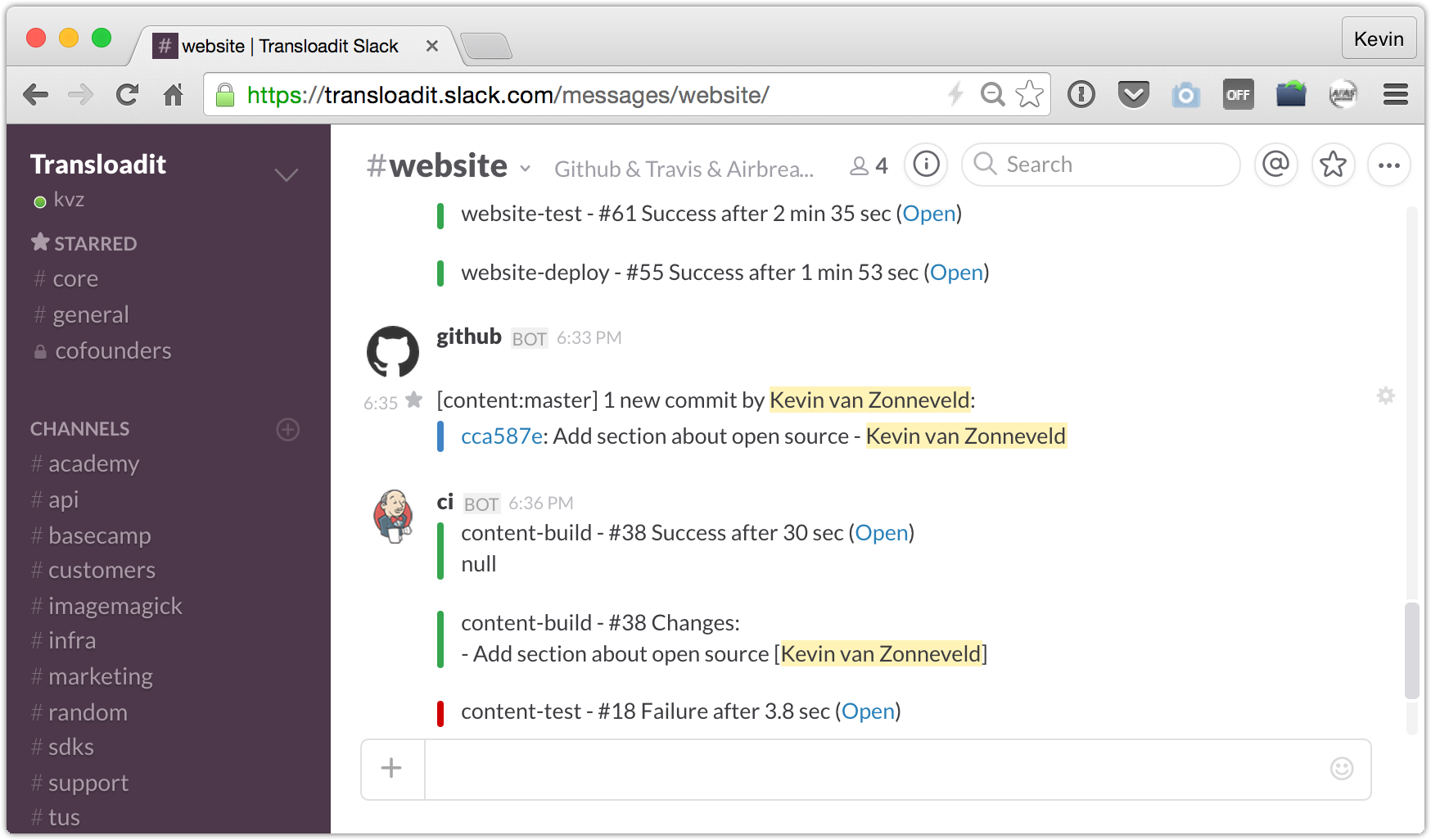
Is this perfect now?
No. Humans are fallible and so are their machines and dictionaries.
We will need to keep tweaking .spelling, and "it" needs to keep correcting me. But with this
automated quality control for language, we keep each other in check, and have less errors than
before.
In the case of Transloadit, we were able to fix 151 mistakes in our first run
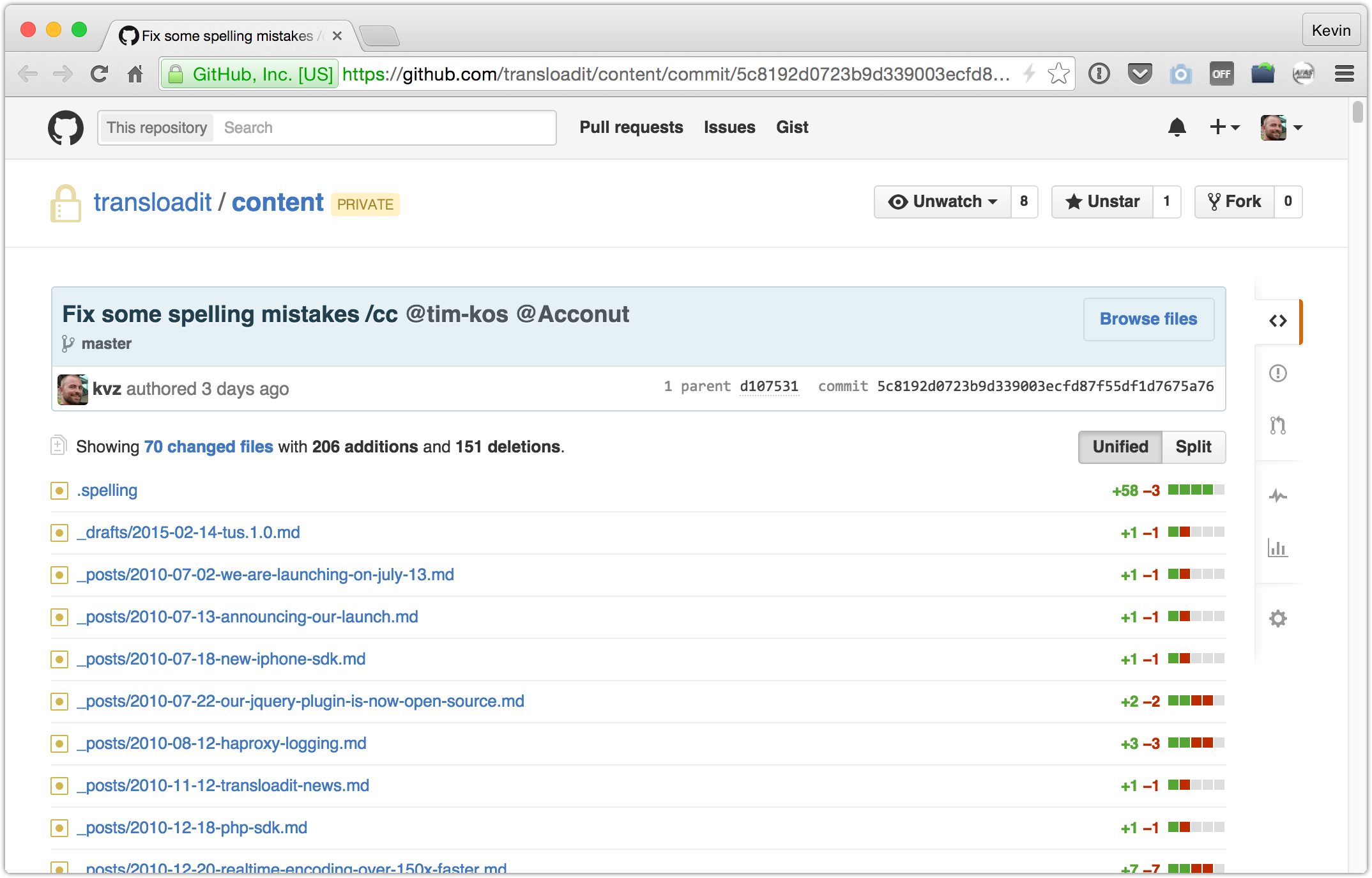
Yes.. it turns out we are were really bad spellers!
What's next
If you know of other cool Markdown processing tools to add to our build chain, let us know on Twitter or comment on HN.
Finally, we are still looking for a good technical writer to help us improve our language, as computers can only get us so far. 😄
Remember that you would only be working on Markdown files, the rest is taken care of automatically. Mail us if you are interested!